Benchmarks
Symbolic API simplifies and speeds up the prototyping
and the development process.
But does it sacrifice performance of the model itself?
One of the most important principles in building this library was to
avoid this.
It was made with performance in mind.
Standard model definition: a class inheriting form torch.nn.Module
is a baseline for us.
Symbolic API aims to create models just as fast in most scenarios.
Note: some features are designed for the convenience and might slow down the models. A good example is
add_to_graphfunction. To get the very best performance, it is crucial to use custom functions and operators insideforwardmethod of atorch.nn.Module. Although even if we don't, the slowdowns should not exceed a few milliseconds.
Tweaks
When using Symbolic Model for performance critical use-case consider
calling optimize_module_calls after all models are created.
from torch import nn
from pytorch_symbolic import Input, SymbolicModel, optimize_module_calls
x = inputs = Input(shape=(3, 32, 32))
x = nn.Identity()(x)
model = SymbolicModel(inputs, x)
optimize_module_calls()
# Here goes:
# * Model training
# * Model inference
# * Model benchmarking
Not using it might give you a small slowdown in CPU limited workflows, but should not affect large models on GPU. We execute it in our benchmarks.
Deep linear model
Pytorch Symbolic won't change the kernel runtime. The only place where it might introduce a slowdown, is before the kernel launches. To see if it does, we will maximize the number of kernel calls.
We will look at a very thin and deep model with linear layers only. Each layer will have only 4 features. If there's any overhead induced by Symbolic Model, it should be visible here. In larger models, the overhead could be hidden by the kernel computation.
Data
Data is randomly generated:
Model definition
from torch import nn
from pytorch_symbolic import Input, SymbolicModel
n_layers = 250 # other used values: 500, 750, 1000
x = inputs = Input(shape=(4,))
for _ in range(n_layers):
x = nn.Linear(4, 4)(x)
model = SymbolicModel(inputs, x)
Inference (CPU)
For such small subsequent matrix multiplications, it can be faster to launch the model on the CPU.
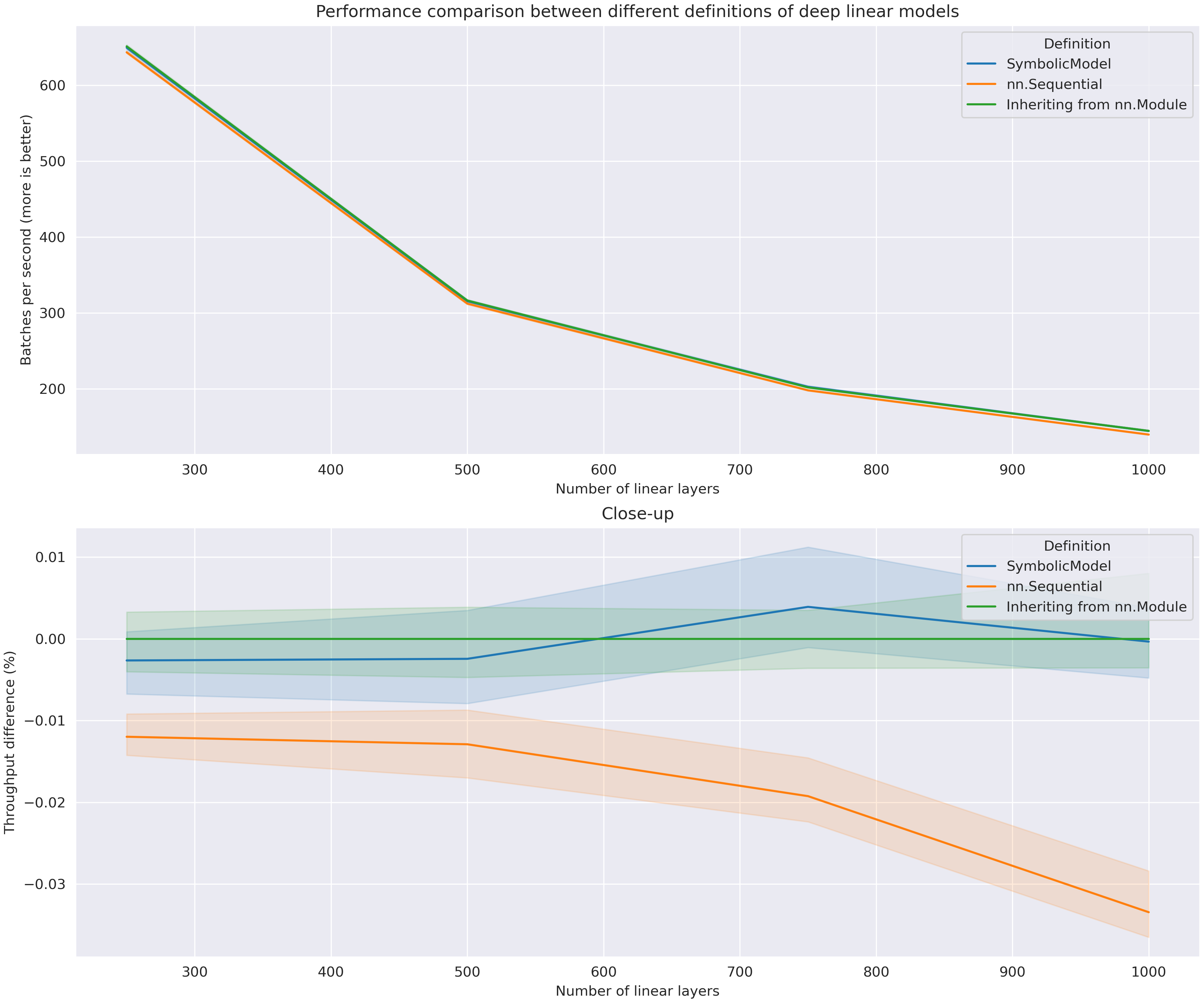
Percentile intervals [25, 75] are visible. Sequential model is visibly slower than the others. This can be explained by the operations introduced by the iterator added in
torch.nn.Sequential. Also, Sequential model seems to be slowing down more as the number of layers increases. The other two models seem to be equally fast!
Toy ResNet
This model is presented in Advanced Topics, it was also used as an example in Keras documentation. It is a shallower and thinner version of commonly used ResNet network.
Data
Data is randomly generated:
Model definition
Definition can be found in Advanced Topics.
Inference (GPU)
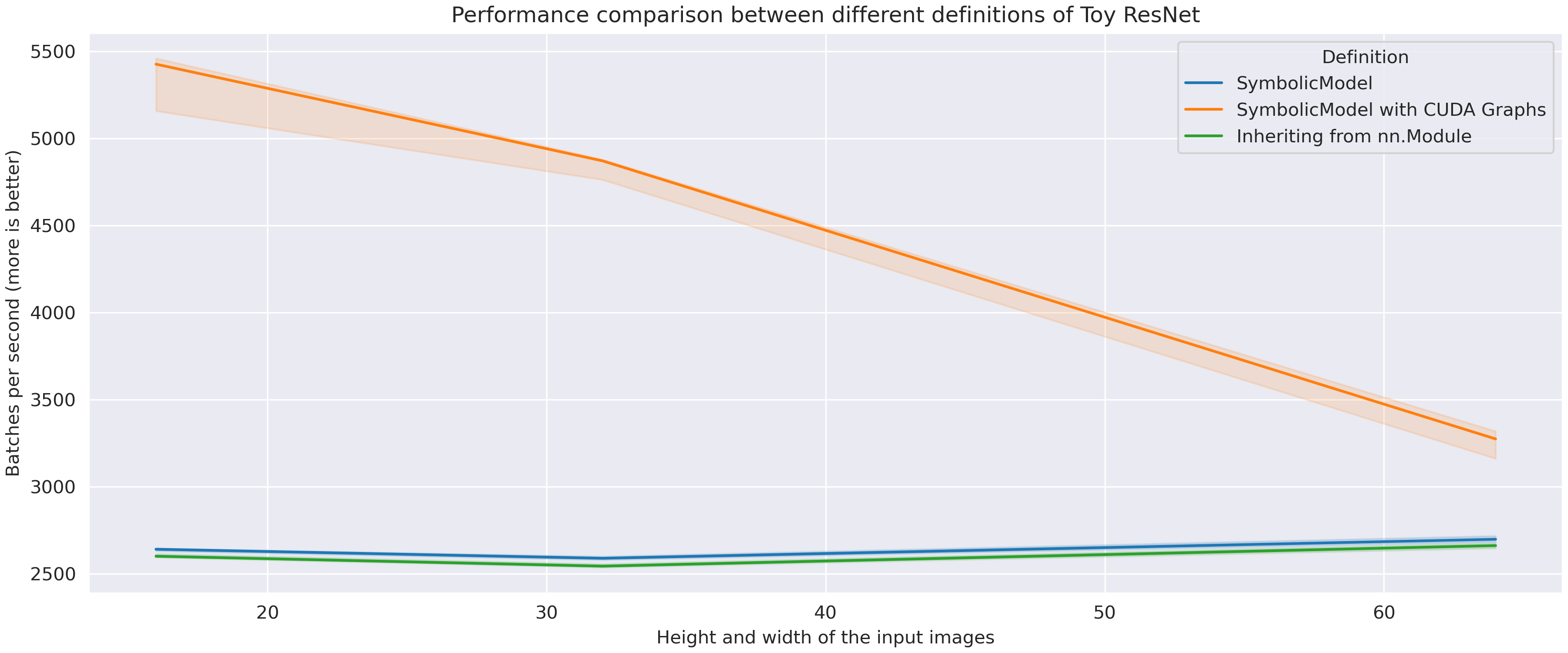
CUDA Graphs have a huge advantage here due to the small batch size and image size. For non CUDA Graphed models GPU is executing kernels much faster than CPU is scheduling the work. This is why we don't see any slowdown when the image resolution increases. Nevertheless, Symbolic Model is slightly faster than the Vanilla model. This is due to some implementation details. For example, it is quite slow to access a layer by
__getattr__in forward function. In Symbolic Model there is no need to do this.
How is Symbolic Model optimized?
Symbolic models reside on underlying graph structures.
Each Symbolic Tensor is a node and each layer is an edge that connects two nodes.
Initially, the forward pass was implemented lazily:
by executing forward in a layer only when
its output was needed by a child node.
But such back-and-forth between parents and children created an unnecessary overhead.
To avoid this, we precompute the exact order in which the layers needs to be called
and use it during forward.
Even when we know the order of the layers, there's one more trick.
Accessing structures has a significant overhead in Python, so we try to avoid it.
When the Symbolic Model is created we dynamically generate code for its forward function.
Thanks to this, Symbolic Model executes exactly the same code it would if you
were to write it as a class.
You can even see the generated code yourself:
def _generated_forward(self, i00, i01):
l = self._execution_order_layers
h09 = i01
for layer in l[0:10]:
h09 = layer(h09)
h19 = i00
for layer in l[10:20]:
h19 = layer(h19)
h20 = l[20](h19, h09)
h21 = l[21](h20)
h22 = l[22](h21)
h32 = h22
for layer in l[23:33]:
h32 = layer(h32)
h42 = h22
for layer in l[33:43]:
h42 = layer(h42)
o00 = l[43](h42, h32)
return o00
CUDA Graphs
Additionaly, with Pytorch Symbolic it's very simple to enable CUDA Graphs when GPU runtime is available. CUDA Graphs are a novel feature in PyTorch that can greatly increase the performance of some models by reducing GPU idle time and removing the overhead caused by CPU making GPU calls.
To enable CUDA Graphs, use:
When using CUDA Graphs, please remember to cast your inputs to GPU. In general, when using CUDA Graphs, you might get some silent errors, for example when you forget to cast your data to GPU. Always check if everything is working without CUDA Graphs before enabling them.
Hardware
Unless stated otherwise, experiments were run on a following PC: